
The AI Stack Problem
Why Claude, Gemini, Grok, Perplexity, and ChatGPT Are No Longer Interchangeable

For a long time, the answer was simple.
Use ChatGPT.
That answer reflected availability, not superiority. The market has since segmented. Capabilities diverged. Interfaces optimized for different workloads.
The relevant question now is practical:
Which model operates best for which task?
This comparison looks at the latest flagship models behind ChatGPT, Claude, Gemini, Grok, and Perplexity. The goal is placement, not ranking.
First question: What are we actually comparing?
A clarification matters.
A model performs inference.
A tool wraps the model in workflow.
Most users evaluate the wrapper and assume they are judging the engine. That assumption breaks down quickly with Perplexity and Grok.
We compare both, but we separate their roles.
ChatGPT — GPT-5.2
Question it solves: How do you maintain continuity over time?
GPT-5.2 is OpenAI’s current flagship model. It powers the top ChatGPT tiers.
Its advantage is not peak output quality. It is state retention.
ChatGPT allows users to:
Maintain project context
Reuse decisions
Operate across long timelines
This matters for workflows that span weeks rather than prompts.
Tradeoffs exist.
External retrieval is conservative. Citation handling is weaker than research-first tools. ChatGPT often prefers internal reasoning over fetching live sources.
Relative performance
GPT-5.2 reflects balance. It rarely fails outright. It also rarely leads decisively. It functions best as a workflow backbone rather than a research engine.
Think reliable infrastructure. Not specialized machinery.
Claude — Opus 4.5
Question it solves: How do you produce high-quality language?
Claude Opus 4.5 sits at the top of Anthropic’s current lineup.
Its strength is language control:
Sentence flow
Structural coherence
Editorial judgment
Claude performs well in drafting and revision. It provides feedback that resembles a competent human editor.
Limits are visible.
The model tends toward embellishment. Over long spans, output density increases even when not requested. Safety constraints are firmer than peers.
Relative performance
Claude Opus 4.5 operates as a language engine. It performs best when text quality is the objective. It performs worse when neutrality or speed dominates.
Use it deliberately. Not everywhere.
Gemini — Gemini 3 Flash
Question it solves: How do you keep prose neutral?
Gemini 3 Flash reflects Google’s design bias toward balance.
The model:
Produces natural dialogue
Avoids stylistic extremes
Maintains consistent tone
This reads as “unremarkable” to some users. That reaction misses the point.
Neutrality is a feature.
Relative performance
Gemini 3 Flash performs well when text should not call attention to itself. Dialogue-heavy writing benefits. Analytical writing remains clean.
It rarely surprises. That predictability is useful.
Grok — Grok 4 / 4.1
Question it solves: How do you reason at scale?
Grok’s advantage is not prose. It is context size and recency.
Capabilities include:
Large context ingestion
Real-time signal analysis
Fast synthesis across long documents
Writing output is functional but uneven. Tone can drift technical. Personality occasionally leaks through. Think enthusiastic engineer, not literary editor.
Relative performance
Grok operates best as a research processor. It handles volume well. It handles immediacy well. It does not optimize for elegance.
Use it where scale matters. Avoid it where style matters.
Perplexity — Multi-Model Orchestration
Question it solves: How do you verify facts efficiently?
Perplexity does not compete at the model level.
It routes queries across:
GPT-5.2
Claude 4.5
Gemini 3
Grok
Proprietary retrieval models
Its interface prioritizes:
Source visibility
Parallel lookup
Citation grounding
Relative performance
Perplexity reflects a different design goal. It optimizes for correctness, not creativity. It performs best when answers must be defensible.
It replaces search more than chat.
Comparative placement
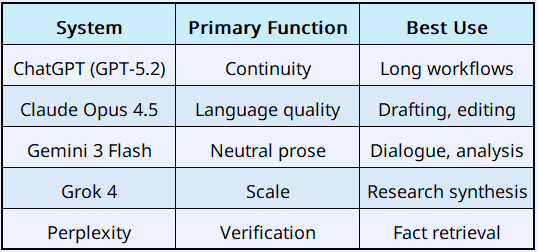
No overlap here is accidental.
Final consideration: The stack, not the tool
The market no longer supports single-tool thinking.
Each system reflects an optimization choice:
Memory
Language
Neutrality
Scale
Verification
Professionals who rely on one interface will plateau. Those who assemble a stack will compound advantage.
ChatGPT was the entry point.
Now the work requires orchestration.
Choose tools the way you choose infrastructure.
Quietly. Deliberately.